MongoDB 도입 계기
- MongoDB 가 가진 여러 가지 장점이 있지만, 그중에서 프로젝트 도입에 가장 큰 영향을 준 기능은 Sharding 입니다.
- MySQL과 같은 RDBMS는 제한 없이 증가하는 사용자의 데이터 저장 시 동일한 스키마의 테이블 명에 인덱스 번호를 붙여 물리적 테이블을 여러 개로 생성하고 애플리케이션 단에서 샤딩을 구현하였습니다.
- 하지만 MongoDB를 사용하면 어플리케이션 단의 Shading을 직접 구현할 필요 없이, Shading이 필요해지는 시점에 Shard 하는 기준이 되는 Shard Key 만 지정한다면 손쉽게 Shading이 가능합니다.
- 아직 서비스의 사용자 데이터가 크지 않아 Shard Set을 여러 개로 구성하지 않았으며 현재 1개의 Shard로 구성하여 서비스 운영하였습니다.

- 현재 프로젝트는 MongoDB 와 함께 RDBMS도 같이 사용하고 있으며, 두 저장소를 나누는 기준은 데이터 사이즈가 제한 없이 늘어나는 데이터 유형을 주로 MonogDB에 저장하고 있습니다.
- MongoDB 에 저장하는 데이터는 사용자의 가고싶어요/갔다왔어요와 같은 관심 장소, 사용자의 리뷰/리뷰 사진/리뷰 좋아요와 같은 데이터입니다.
- RDBMS에는 POI 데이터와 회원 정보 및 각종 설정과 어드민 관련한 데이터들을 저장하고 있습니다.
MongoDB 써보니 좋은 점
- Flexible Schema
- 테이터를 삽입하기 전에 테이블의 스키마를 결정하고 선언해야 하는 SQL 데이터베이스와 달리 MongoDB의 컬렉션은 기본적으로 문서에 동일한 스키마 필요하지 않습니다.
- RDBMS로 개발할 때는 테이블에 칼럼을 추가 및 변경할 때 Alter와 같은 DDL 문을 실행해야 했지만, MongoDB는 저장할 도큐먼트 Java 클래스에 변수 선언을 추가하는 것만으로 필드 추가가 가능합니다.

- Document Structure

-
- 비 정규화된 데이터 모델을 통해 응용 프로그램에서 여러 개의 테이블을 조인할 필요 없이 한 번에 관련 데이터를 검색하고 조작할 수 있습니다.
- 문서 내에 배열 또한 저장이 가능하다는 것은 큰 장점입니다.
- 하나의 도규먼트는 16M까지만 지원이 가능하다는 제약사항이 있습니다.
- 배열이 변경이 빈번한 경우 복제 시 전체 배열 값이 전달되기 때문에 성능 이슈가 발생할 수 있습니다.
- 배열의 사이즈가 무제한 늘어날 수 있는 경우 별도의 컬렉션에 분리하여 저장하여야 한다. one-to-many 지만 사이즈 제한이 있다면 embeded 가능하며 one-to-zillions 이라면 별도의 콜렉션으로 저장해야 합니다.
- 화면 뷰 관점 설계

리뷰를 조회할 때 최신 댓글 일부만 노출이 필요하다면, Article에 최신 댓글을 저장하고, 댓글 전체는 별도 콜렉션에 저장합니다. 이렇게 One-Many 관계에서 many 중 일부를 one에 Embeded 하도록 설계할 경우 리뷰를 조회 시 댓글 컬렉션을 추가적으로 조회할 필요가 없습니다. 본문의 태그의 경우에는 본문에서 태그만 뽑아서 Tags 배열에 저장하면 해당 태그에 속한 리뷰 리스트 조회가 가능합니다.

- 컴파운트 공간 인덱스 지원
-
RDBMS에서는 일반 칼럼(1차원 데이터)과 R-Tree 인덱스를 묶어서 결합 인덱스(컴파운드 인덱스)를 생성할 수 없습니다.
- MongoDB 는 내부적으로 S2 Geometry 라이브러리를 이용해서 2차원 데이터를 1차원 데이터로 변환한 다음 인덱스를 생성하므로 결합 인덱스 생성 가능합니다.
- 프로젝트 내에 사용자의 가고싶어요/갔다왔어요 관심장소를 저장하고 조회 시 "사용자번호 + 관심장소 geometry + 관심장소유형" 의 컴파운트 공간 인덱스를 통해 검색 범위를 좁혀 빠르게 조회가 가능하였습니다.
- 이 경우 반드시 모든 공간 검색 쿼리는 "사용자번호" 필드를 가지고 있어야 합니다.
- "사용자번호" 가 들어가지 않은 공간 검색 쿼리가 필요하다면 공간 인덱스를 추가로 생성해야 합니다.
-
MongoDB 써보니 불편한 점
- Join이 제한적
- 3.2 버전에서 새롭게 추가된 기능인 $lookup을 통해 left outer join이 가능합니다.

- 샤딩된 컬렉션은 lookup을 사용할 수 없습니다.
- 쿼리 문법이 익숙하지 않을 수 있습니다.
- GUI 툴에서 쿼리를 만들고 Java 문법으로 변환하는 과정이 필요합니다.


디버그 로그 확인

알아두면 좋은 팁
- Schema Design Patterns
- 애플리케이션의 성능이 제대로 나오지 않는 것은 대부분 Schema 디자인이 잘못 되었기 때문이다. 어플리케이션 특성에 맞는 스키마 디자인 패턴을 알고 있다면 보다 좋은 애플리케이션을 만들 수 있습니다.
- Flexible Schema 이기 때문에 잘못 설계된 Schema 라도 Document Versioning 패턴을 활용한다면 Schema 디자인을 점진적으로 개선해 나갈 수 있습니다.
- GUI for MongoDB
- MongoDB Compass : MongoDB 에서 무료로 지원하는 툴로 Aggregation 쿼리 작성 시 각 stage 별로 쿼리 결과로 시각화할 수 있어서 편리하다. 또한 geometry 정보를 시각화해서 보여주는 기능도 제공합니다.
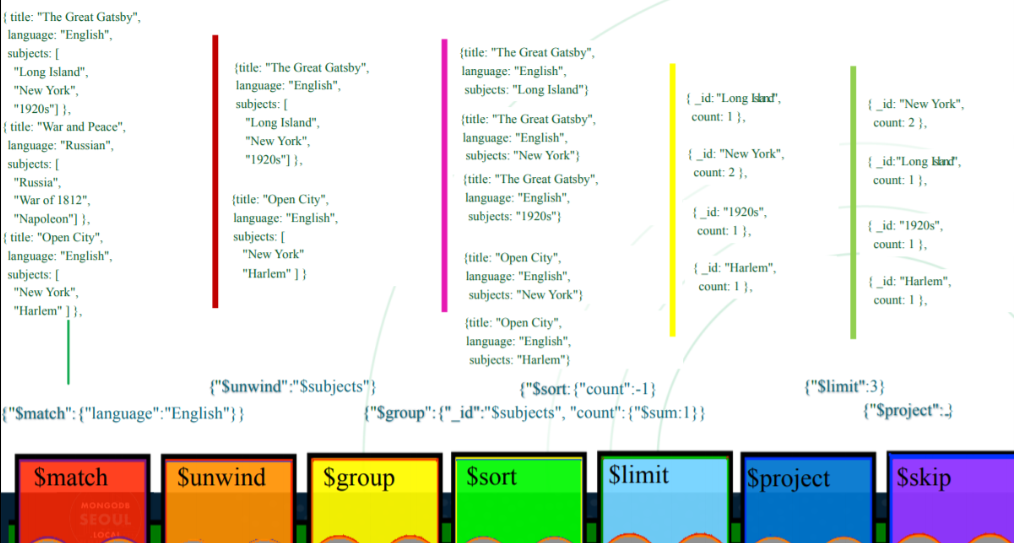

-
-
- NoSQL booster : 자동완성 기능을 제공하지만, 일정 기간이 지나면 유료 라이선스가 필요합니다.
- Studio 3T
- Spring Data MongoDB
- 단순한 쿼리는 MongoRepository를 사용하여 구현하고 Aggregation이나 lookup 등 복잡한 쿼리는 MongoTemplate를 사용하여 구현하였습니다.
-
마치며
현재 네이버, 카카오 등 국내 140여 기업이 몽고 DB를 사용하고 있으며, 2018년 한국 지사를 설립하고 많은 홍보와 세미나를 진행하고 있습니다.
몽고 DB는 클라우드를 기반으로 하는 서비스 추세에 맞추어 AWS, Azure, Google Cloud Platform에서도 사용 가능한 몽고 DB Altas라는 클라우드 기반 서비스를 제공하고 있습니다. 무료로 테스트 용 서버를 구축하고 샘플 데이터를 넣고 확인할 수 있으니 관심이 있는 분들은 한번 써보는 것도 좋을 것 같습니다.
또한 MongoDB University를 통해서 기본적인 쿼리 문법에서부터 데이터 모델링까지 다양한 교육을 지원합니다.
강의는 Chapter 별로 5분 내외라서 지루하지 않게 들을 수 있으며, 몽고 DB Altas를 통해 실습 문제도 진행이 가능합니다. 강의는 영어로 진행되지만 영문 자막과 영문 스크립트가 제공되며 앱을 통해 모바일로도 강의를 들을 수 있습니다.
현재 몽고 DB는 v4.2 버전으로 업그레이드되었으며, 지난 10년간 성능이 많이 개선되었으므로 새로운 프로젝트에 도입하여 몽고 DB가 제공하는 장점들을 활용해 볼 만한 가치가 있다고 판단됩니다.
참고
'프로그래밍 > MongoDB' 카테고리의 다른 글
| MongoDB Docker-compose Replica (0) | 2021.06.25 |
|---|---|
| [2월 25일] 온라인 세션 'MongoDB University 교육과정과 Certification에 대한 모든 것' (0) | 2021.02.16 |
| M320 Data Modeling (0) | 2020.08.05 |
| M001 MongoDB Basics (0) | 2020.08.05 |
| 대용량 데이터 처리를 위한 Real MongoDB (0) | 2020.08.05 |
| 몽고DB_BACK_TO_THE_BASIC (0) | 2020.08.05 |



